This summer series will highlight weekly blog posts from this year’s UW Data Science for Social Good Fellows.
“Parallel worlds of pangolin conservation and Data Science for Social Good” by Hyeon Jeong Kim, Data Science for Social Good Fellow

This summer I am working as a fellow in the Data Science for Social Good Program (DSSG) at the eScience Institute, University of Washington. With four other fellows, I am working on a project we affectionately call ‘seamo’ – a diminutive form of the ‘Seattle Mobility Index’ project. We are developing three indices of mobility in Seattle: transport mode choice, affordability, and reliability. Each of the indices measures a vital part of a Seattleite’s ability to live, work, and enjoy Seattle. These scores provide a standard way of understanding and communicating mobility and a means to evaluate geographic equitability of mobility to inform policy.
The rest of the year, I am a short distance away in the Biology Department at the university, but immersed worlds away in the field of conservation biology as a PhD student. My research goal is to identify poaching hotspots of the most trafficked mammal in the world, pangolins, to inform conservation management and wildlife enforcement decisions. This translates into a lot of time looking for pangolin scats in forests with detection dogs, extracting DNA from pangolin specimens in museums, and conducting genetic analyses in labs.
Coming into DSSG, I was expecting an entirely foreign world. Data science? Social good? Human-centered design? All were completely new concepts to me. However, as the project unfolded, there were similarities between biodiversity conservation and a DSSG project. The three common themes that emerged were: stakeholder-inclusive project design, adaptive process, and ‘social good’ outcomes.
At DSSG, there was an emphasis on the analysis and inclusion of stakeholders from the very beginning. For seamo, we were fortunate enough to have the main stakeholders of the project, the Seattle Department of Transportation (SDOT), as the project leads, with whom we can brainstorm, discuss, and ask questions at each point of crucial decisions. In addition, we had a meeting with an extended panel of stakeholders from SDOT and the Office of the Mayor. We developed a system to exchange information and provide feedback resulting in continued interactions that were invaluable in gaining insight into the specific interests and the potential uses of the Seattle Mobility Index.
In conservation biology, there has been a call for increased stakeholder inclusion and participation in project and management design. The critters or habitat we are working to protect are part of a much larger ecosystem that is intricately woven into people’s lives, society, and governments. Pangolins are distributed over two continents in over 47 countries and have long been a part of people’s livelihood and traditional medicine. I am aware that the decisions made on the conservation of pangolins will undoubtedly have an effect on a wide-range of communities and the goal is to capture the social dimensions of conservation before research is conducted and decisions are made. However, the breadth of conservation projects makes this a challenge, especially for a project that spans multiple species, countries, and continents.
Having heard the views of Seattle Mobility Index stakeholders, the seamo team has adjusted its course to take account of the feedback. The main addition to the project was the development of personas that represent key groups of people living in Seattle. The purpose of the personas is to add a filter to the Seattle Mobility Index to show what mobility looks like for different types of people. The mobility index of a single professional who likes to bike everywhere will look different from a family with two children that uses a car as the primary mode of travel. Along with this major addition of personas, we made a number of smaller adjustments to the project that we did not foresee at the beginning. The continued feedback from our stakeholders has kept us flexible and each mobility index has gone through a number of iterations to provide the most informative score for the stakeholders.
Researchers and policy makers in conservation biology strive to practice ‘adaptive management’. Adaptive management is an iterative process where the outcomes of management decisions are measured, and the resulting data is used to adjust the decisions. This feedback mechanism allows for flexibility to better deal with the vast levels of uncertainty in conservation. As my research progresses, I believe this iterative approach will be crucial for pangolins. There is so much unknown about pangolin biology, ecology, habitat, and behavior that when it comes to these eight elusive and shy animals, decisions are being made in a sea of uncertainty. Iterating over monitoring approaches will provide the flexibility needed to gather the information and course-correct on the management decisions. Being adaptive gives us the best hope to ensure the continued survival of these species in the wild.
Finally, both DSSG and conservation biology dwell heavily on the potential outcomes of a project to ensure social good and that no harm is done. For seamo, the same considerations are made – there is an emphasis on identifying both positive and potential negative users to ensure that we are aware of results of our project. We ponder on the positive and negative outcomes of the project now so that we can ensure that seamo is not only intended to do good, but that it will do good. In my research, I consider the impact I may leave in an ecosystem by my team’s presence while searching for scat samples, I am careful about who has access to the location of these scat samples, and I worry about the consequences that my research may have on the people and communities. I will be taking the lessons learned in seamo with me as I move forward with my research on pangolins.
————
“A quicker recipe” by Chris Haberland, Data Science for Social Good Fellow
A few weeks into my fellowship with the Data Science for Social Good (DSSG) program at the eScience Institute, my family gifted me a “smart” pressure cooker for my birthday. Initially, I was afraid to take it out of the box and unleash the onus of having to learn a whole new method of cooking. A few days after its receipt, I summoned the courage to unwrap it from its heavy packaging and plugged it in. It made a friendly electronic sound, but I was a bit fearful of it exploding if I pressed the wrong button.
Eventually, though, I read the manual. I searched for recipes online. I visited bookstores to peruse their pressure cooker cookbooks. After just a few weeks, I felt like an alimentary genius; I now aver to passersby that the pressure cooker has changed my life for the better. For far too long, I had dismissed this magical gadget that allows me to make hot, flavorful, fragrant cuisine in a fraction of the time and effort of using a stove or oven. If only I had been aware of its sorcery sooner, I could have avoided years of heartbreak in the kitchen.
As a data science fellow this summer on the Disaster Damage Detection team with the Data Science for Social Good program at the University of Washington eScience Institute, I’m learning the paramount importance of reading the documentation of new gadgets that my team recommends to “pressure cook” my problems and reduce the effect of bad practices and dull tools that could mire my workflow.
Upon hearing of a new method to facilitate a data-wrangling task, my initial reaction is often lethargic. After all, it can be inconvenient to download and install new software programs or Python packages that might lead to more problems if they don’t work as planned. Sometimes I just want to “brute force” my way into solving a problem with what I already know: the traditional stovetop and wooden spoon in my coding tool cupboard.
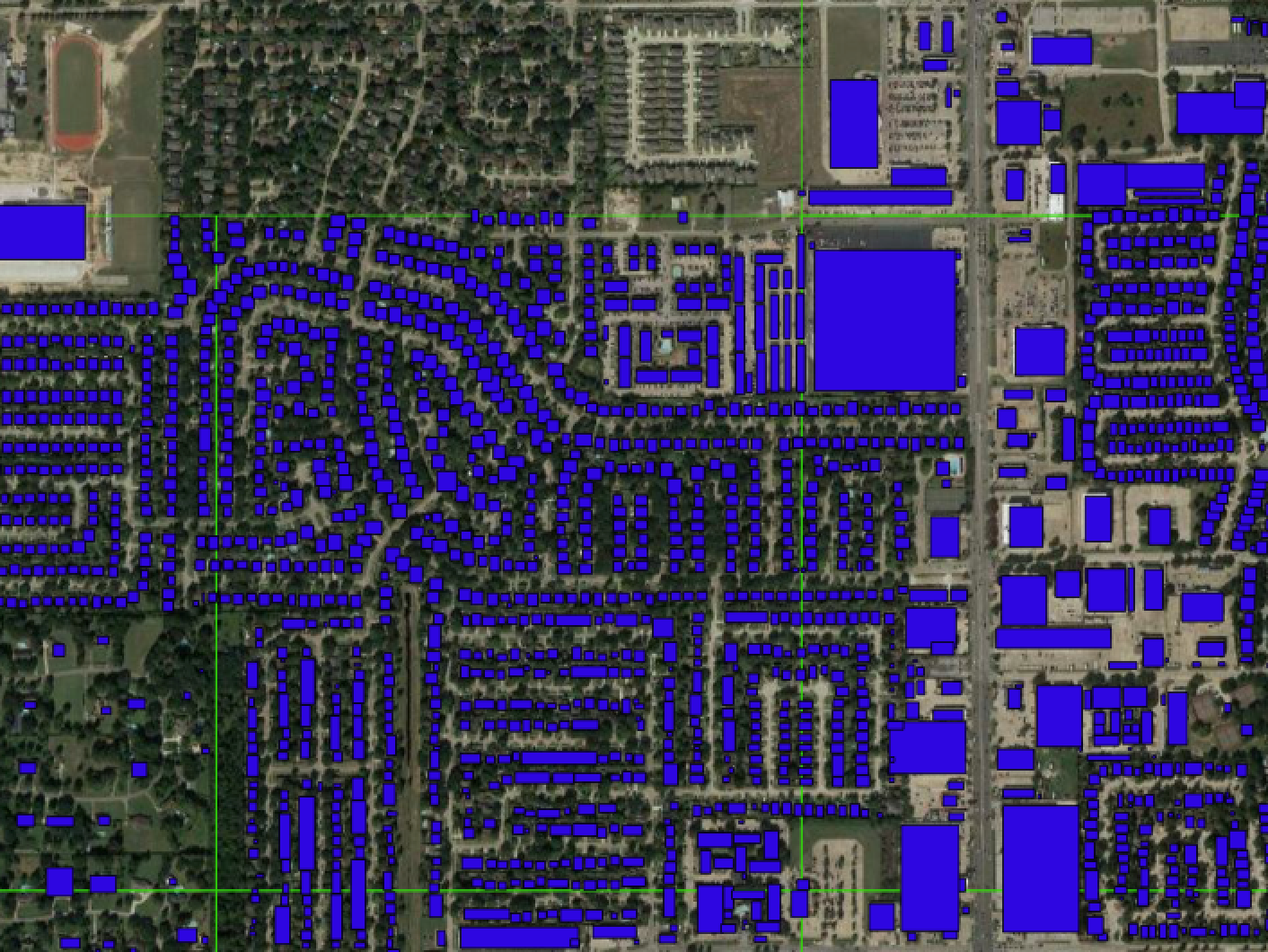
For our project, a major task has been importing and preprocessing geospatial data to train an object detection algorithm that will help the team to identify damaged buildings from post-hurricane satellite imagery. At times, the going has been tough. Anyone who has worked with large amounts of geospatial data understands that GIS processing is not always the most efficient. Load times of large data in standard formats can be infinite. The proper formatting of geospatial data often requires numerous intermediate steps that can stall out if the CPU memory is insufficient for the task at hand. Moreover, the analyst needs a shopping list of data wrangling steps to avoid unnecessary mistakes.
A few weeks after making my first minestrone in my pressure cooker, I imported a Microsoft Building Footprints data set for Texas, which contained millions of polygons, into QGIS, a standard open-source GIS program. I was relieved when this operation did not crash everything and the polygons loaded in a little under a minute. The next task in my pipeline involved selecting the polygons just inside our study area of interest. I initiated the process, but the progress bar stalled and I received an unhelpful error message. After running a few tests, it became clear that the sheer size of the dataset was causing the issue. My team was waiting. The heat was on but nothing was cooking – not even slowly.
Eventually, I told my team about the holdup, and another fellow informed me that PostGIS, an extension to QGIS, might be able to run the operation without a problem. PostGIS uses the relational database framework PostgresQL to increase the efficiency of many geospatial operations for large datasets, but using it would require me to delve into several other programs that might produce their own errors. I’d need to learn how to run a whole complementary set of tools and commands for running an operation that would have been so simple using what tools I already knew (had they worked!). But data in its current form was still not palatable.
I should take my fellow fellow’s advice to learn about PostGIS and “pressure cook” this data, I thought. I downloaded new programs to instantiate the data as a PostgresQL database. I read tutorials to learn new SQL recipes. I ran the process using a new paradigm, and rejoiced when QGIS finally generated output that the object detection algorithm could sink its teeth into. I thanked my teammate for the helpful tip leading me to resolution, and I thanked myself for endeavoring to learn yet another gadget. The taste of success was so satisfying.
————
“Reflections on reproducibility of data science projects” by An Yan, Data Science for Social Good Fellow
For the past nine weeks, I have been part of a data science project whose aim is to identify damaged or flooded buildings after a hurricane event from satellite imagery. Aside from the research experience and technical skills gained through the project, I am thrilled to learn that the eScience Institute at University of Washington emphasizes a great deal of data management and reproducibility: this is the sort of culture not often seen in other academic environments. As I am also working on another ongoing project which surveys Earth System Science researchers about their experiences in data reuse and reproducible research, I feel an impetus to share my thoughts on the definitions of reproducibility, current awareness of reproducibility in the data science community, and some good practices for enhancing reproducibility.
What is research reproducibility?
Reproducibility of research results is an important metric to judge the validity of scientific findings. Scientists hold that only scientific research that can be replicated or reproduced independently by others is considered as trustworthy [1]. However, there is no consensus on what reproducibility means. According to the U.S. National Science Foundation (NSF) [2], reproducibility “refers to the ability of a researcher to duplicate the results of a prior study using the same materials as were used by the original investigator.” Here I adopt the definitions proposed by Goodman et al., which detangle the concept of “reproducibility” into different phases of research [3] :
- Method reproducibility means that using the same procedures and data as the original researcher, another researcher should be able to re-execute the research process. In this case, sufficient details of the original research need to be provided.
- Result reproducibility refers to the ability of an independent researcher to obtain the same result with a similar method as the original study.
- Inferential reproducibility refers to drawing similar qualitative conclusions from the results of a replication study or from the results of the original study. Sometimes different conclusions could be drawn from the same results and the same conclusions could be arrived at from different but similar analytical results.
I would also add “data reproducibility”, which is important to data science as datasets produced from projects are increasingly recognized as important research outputs and often get reused by others. Data reproducibility refers to the reproduction of the same or similar datasets using the method described by the original study. This requires sufficient documentation of data processing steps as well as access to the source data used.
Reproducibility in data science
In the past decade, research reproducibility has been a hot topic in fields such as psychology, biology, and medical research. Recently, the machine learning community began to pay attention to this issue. For example, the International Conference on Machine Learning (ICML) organized Reproducibility in Machine Learning Workshops in 2017 and 2018. The International Conference on Learning Representations also launched a reproducibility challenge in 2018, in which Joelle Pineau delivered an inspiring talk on Reproducibility, Reusability, and Robustness in Deep Reinforcement Learning. She proposed that machine learning and reinforcement learning communities should use “reusable materials (software, datasets, experimental platforms), actively participate in reproducing scientific methods, and develop a culture of good experimental practices”.
In my opinion, the general rule for making research reproducible is to make it “reproducible by design”, that is, researchers should keep in mind the fact that someone else will reproduce their work someday, and take that future “reproducer’s” need into consideration while designing each phase of the study.
Good practices for making data science projects reproducible
Let us examine how data science projects can achieve data reproducibility, method reproducibility, result reproducibility, and inferential reproducibility.
Data reproducibility
To make datasets reproducible, it is critical to provide access to the source materials and any code or tools used to process the source data. In our project, all the data and tools used are open-source. We use a Github repository to manage all our data processing scripts and document the data pipeline. By following the instructions on this repository, others should be able to reproduce any intermediate data used by our team. There are some cases when it is not possible to exactly reproduce datasets. For example, machine learning projects often use human annotators to create training data. These training data are subject to human biases and random mistakes. It would be very helpful to establish a standard procedure and quality check for the human annotation phase and document everything in reasonable detail. It is also difficult to recreate observational data and field experiment data. Again, sufficient documentation of how data is generated would be helpful to others.
Method reproducibility
Data science can be computationally heavy. Thanks to the thriving open-source community today, many software programs and libraries are freely available to anyone, making exact replication much easier than in the old days. Apart from providing access to code and tools used in the research, documentation of method is also vital in ensuring method reproducibility. With enough details, another researcher would, in theory, be able to reimplement the methods even when the code and tools used by the original study are not available. There are many good practices to document research methods besides papers and their supplemental materials, including executable notebooks such as iPython notebook, readable code comments, and Github Wiki pages. Our team uses all of the above mentioned tools to keep things organized.
Result reproducibility
Exact replication can identify mistakes in data and method. However, with the same or similar research questions, reproducing a study using different data or methods can judge the validity and test the robustness of a claim. For example, this can include conducting research in a different geographic area from but with the same method as the original study. To ensure result reproducibility, one good practice is to repeat the study multiple times with different subsamples of data before arriving at any final result. In our project, we applied an object detection method to imagery of Hurricane Harvey. One of our future goals is to incorporate data from other events, test the generalizability of our model and then try to make it more generalizable.
Inferential reproducibility
When conducting data-driven social science research, there is a caveat that the study should be built on some social science theories and the data used is fit for the purpose of the study. Professor Rob Kitchin brought up three risks of applying big data to social science. One of the risks is that “through the application of agnostic data analytics, the data can speak for themselves free of human bias or framing and that any patterns and relationships within big data are inherently meaningful and truthful”.
To summarize, research reproducibility has become a concern for the data science community. Reproducibility can be examined through data reproducibility, method reproducibility, result reproducibility, and inferential reproducibility. Although in some cases, exact replication is not possible, providing open access to raw materials and documenting details of the research process are of utmost importance. There are many changes in culture, reward structures, and funding policies that need to happen in the long run, but as researchers, adopting good practices can make a difference in a short period of time.
References:
1. Laine, C., Goodman, S.N., Griswold, M.E. and Sox, H.C (2007). Reproducible research: moving toward research the public can really trust. Annals of Internal Medicine, 146 (6). 450 – 453.
2. K. Bollen, J. T. Cacioppo, R. Kaplan, J. Krosnick, J. L. Olds, Social, Behavioral, and Economic Sciences Perspectives on Robust and Reliable Science (National Science Foundation, Arlington, VA, 2015).
3. Goodman, S. N., Fanelli, D., & Ioannidis, J. P. (2016). What does research reproducibility mean? Science Translational Medicine, 8v(341), 341ps12–341ps12.
4. Kitchin, Rob. “Big data and human geography: Opportunities, challenges and risks.” Dialogues in human geography 3.3 (2013): 262-267.