On August 18th, student fellows at the eScience Institute’s Data Science for Social Good (DSSG) program presented the results of their 10-week summer projects on the topics of fairness in computational redistricting, and the impacts of Seattle’s minimum wage ordinance in relation to residential displacement and commuting patterns. The student fellows conducted their work on two interdisciplinary teams, working with project leads and data scientists.
The DSSG program at the University of Washington (UW) joins students from universities around the country with data and domain researchers to work on collaborative projects for societal benefit. The program incorporates tutorials and workshops on technical and ethical issues, and engagement with stakeholders who are unique to each project, to generate results that are grounded in real-world applications. This year the program took place remotely for the second time due to the coronavirus pandemic.
The event featured opening remarks by UW College of Engineering Dean Nancy Allbritton, and two representatives of Micron Technology: Erik Byers, Vice President of DRAM-Emerging Memory Process Development, and Scott Gatzemeier, Vice President of Yield, Technology and Data Science. More than 100 people watched the final presentations, which took place via zoom. The recording is available here.
Dean Allbritton, who also spoke at last year’s final presentations, said, “It’s just amazing, the enthusiasm and creativeness from our students just keeps rolling out. This program is a perfect way to showcase not only social impact but collaborations across so many different disciplines, people coming to work together to solve important problems that our society is challenged with.” She noted that social good is a core component of the strategic plan at the College of Engineering.
Byers and Gatzemeier highlighted how the DSSG supports Micron’s mission to: “Transform how the world uses information to enrich life for all,” with Gatzemeier noting that, “The skills that you’re learning as you go through this program – such as exploratory data analysis, coding languages, modeling techniques, machine learning and visualization tools are all transferable skills that we leverage to develop our products at Micron.”
Byers said about the DSSG projects, “These are complicated, sometimes controversial topics. But these are conversations that need to happen, as hard as they might be. One thing that really amazes me is these teams’ ability to take these super complex problems and topics, use data science to draw objective conclusions and recommendations, and make it look simple to do in the process,” Byers said.
For the second year in a row, the DSSG program partnered with the Micron Foundation as a recipient of Micron’s Advancing Curiosity Award. Through this partnership, the DSSG offered the Micron Opportunity Award to students requiring additional financial support to participate in the program. Micron also supported student fellow stipends and resources for remote work. The DSSG program also receives generous and continuing support from the UW.
Descriptions of this year’s two projects and their final outcomes are below:
Geography, Equity, and the Seattle $15 Minimum Wage Ordinance
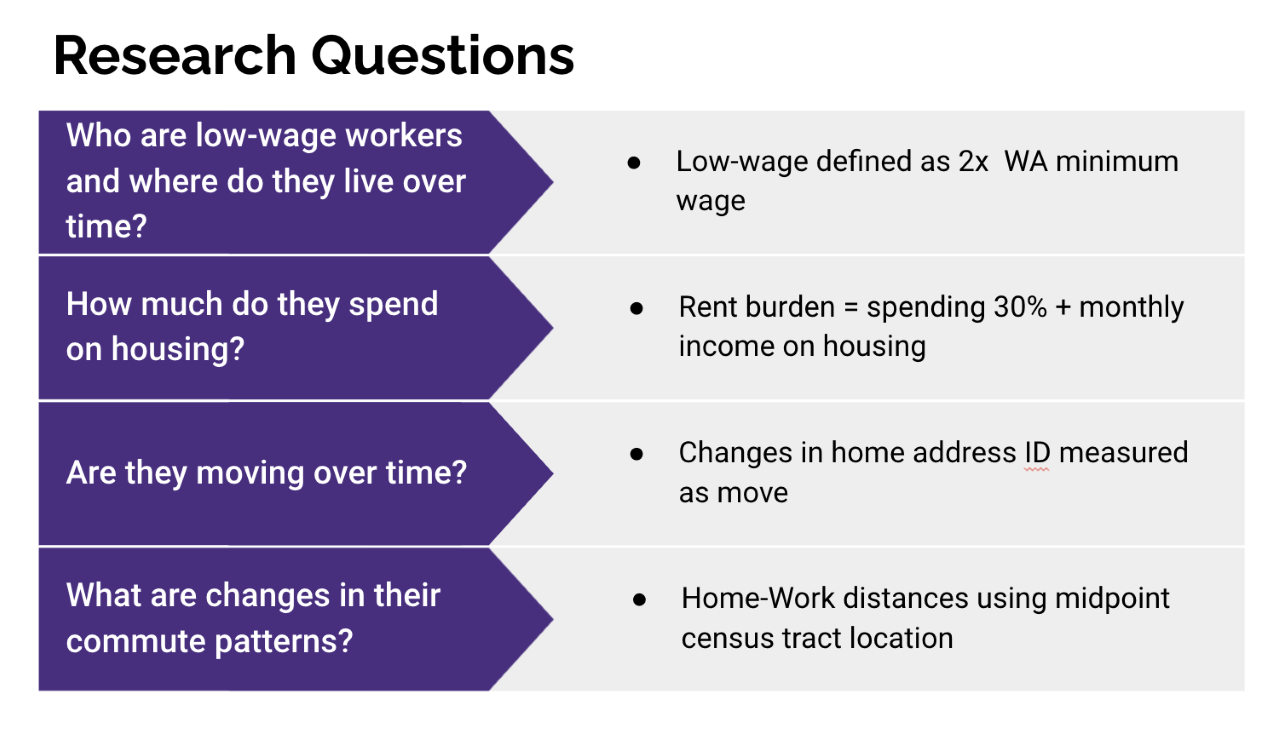 This project explores the impacts of Seattle’s $15 minimum wage ordinance on low-wage workers in the context of the city’s coinciding tech boom and growth in wealth. The team looked at data before and after the law took effect in 2015 to identify trends in the geographic distribution of workers in the Puget Sound region. They defined low-wage workers as those making twice the minimum wage, and estimated commuting distances using midpoint census tract locations corresponding to home and work addresses to protect privacy. They built maps showing the proportion of low-wage workers who live in each census tract, and the proportion in each area who are considered housing burdened (spending more than 30% of their income on rent), across multiple years. They also created a graph showing workers’ residential changes over time, and examined the number of moves as a potential indicator of displacement.
This project explores the impacts of Seattle’s $15 minimum wage ordinance on low-wage workers in the context of the city’s coinciding tech boom and growth in wealth. The team looked at data before and after the law took effect in 2015 to identify trends in the geographic distribution of workers in the Puget Sound region. They defined low-wage workers as those making twice the minimum wage, and estimated commuting distances using midpoint census tract locations corresponding to home and work addresses to protect privacy. They built maps showing the proportion of low-wage workers who live in each census tract, and the proportion in each area who are considered housing burdened (spending more than 30% of their income on rent), across multiple years. They also created a graph showing workers’ residential changes over time, and examined the number of moves as a potential indicator of displacement.
The project utilized the Washington Merged Longitudinal Administrative Data (WMLAD), a comprehensive state-level geocoded dataset that provides administrative data on employment and earnings outcomes. Project lead Jennie Romich and multiple collaborators created WMLAD over the past five years with the help of seven state agencies, in connection with the ongoing UW Minimum Wage Study. Accessing WMLAD requires a specialized workflow, as the data is kept in an offline enclave by the UW Center for Studies in Demography & Ecology to protect privacy.
An exploratory analysis of WMLAD data from 2010 to 2017 yielded the following results:
- Low-wage workers were likely to move 4+ times over the time period studied, compared with an average of 2 moves for all Washingtonians;
- The number of non-low wage workers living in Seattle increased over time;
- The proportion of low-wage workers living within the city decreased while the proportion of those living in the outskirts and outside of Seattle increased;
- Total moves increased and peaked in 2015, before dropping.
The student fellows for this project were Delaney Glass, a Ph.D. student in biological anthropology at UW; Lamar Foster, a Ph.D. candidate in the Education Policy, Organizations, and Leadership program at the UW College of Education; Christopher Salazar, an incoming Ph.D. student in Industrial and Systems Engineering at UW; and Mahader Tamene, a Ph.D. student in the Division of Epidemiology at University of California, Berkeley’s School of Public Health. Romich, the project lead, is a Professor of Social Welfare at the UW School of Social Work and Faculty Director of the West Coast Poverty Center. The data scientists were Valentina Staneva and Jose M. Hernandez, Senior Data Scientists at the eScience Institute.
Learn more on the project blog and project website.
Using Ensemble Methods for Computational Redistricting
 This project informs the state-based congressional redistricting process that occurs every 10 years, and is currently underway, to reflect changes in the U.S. Census. The team created a stakeholder guide to make the computational redistricting tool GerryChain more accessible to citizen groups, activists, and non-partisan map-drawing commissions. The guide can be used to monitor maps produced by redistricting committees for potential gerrymandering, or the strategic manipulation of electoral districts to benefit partisan or racial groups. GerryChain is a Python library for generating a distribution (“ensemble”) of possible district maps using Markov Chain Monte Carlo. A Markov chain is a special sequence of random variables, where the distribution of each variable only depends on the outcome of the previous variable.
This project informs the state-based congressional redistricting process that occurs every 10 years, and is currently underway, to reflect changes in the U.S. Census. The team created a stakeholder guide to make the computational redistricting tool GerryChain more accessible to citizen groups, activists, and non-partisan map-drawing commissions. The guide can be used to monitor maps produced by redistricting committees for potential gerrymandering, or the strategic manipulation of electoral districts to benefit partisan or racial groups. GerryChain is a Python library for generating a distribution (“ensemble”) of possible district maps using Markov Chain Monte Carlo. A Markov chain is a special sequence of random variables, where the distribution of each variable only depends on the outcome of the previous variable.
The guide, which is available on the project website, provides generalizable rules for GerryChain users who are analyzing the redistricting process in any state, and may be used to challenge maps in court. The guide covers the analysis process from data wrangling through calculating and interpreting metrics; and provides three case studies that the team conducted to highlight the nuances of modeling based on state-based redistricting rules. They are as follows:
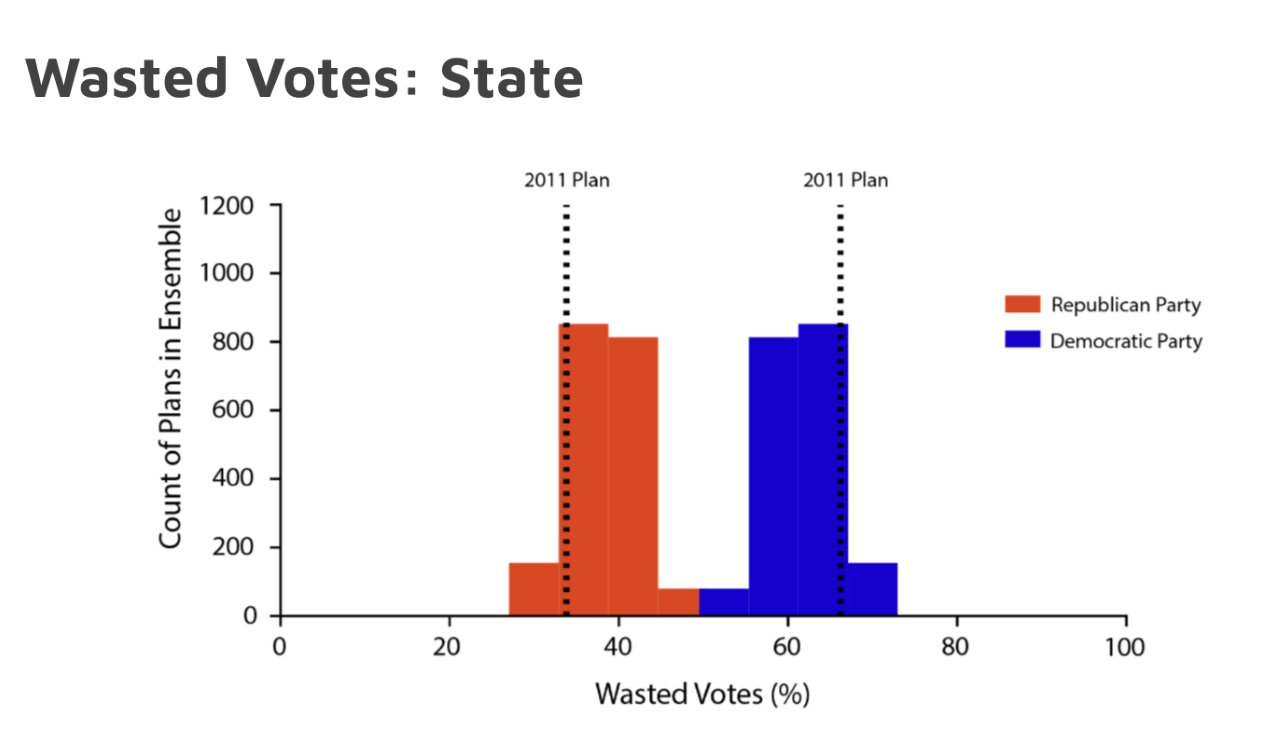
- Georgia: The team examined a built-in GerryChain metric on “wasted votes”, or any votes cast for either party in excess of the 50% needed to win, to explore a state rule about evaluating partisan outcomes. They generated an ensemble of 2,000 proposed plans, measured the wasted vote counts per district, calculated total percentages of wasted votes for each party, and compared the outcomes to the 2011 district map using 2016 presidential election data.
- Colorado: The team generated an ensemble that would “maximize the number of politically competitive districts,” as required by state law. They used the “vote band” method, considering a district to be competitive if its Democratic and Republican vote shares fell within the 45-55% range. They designed a Markov chain to only accept next steps that contain plans with the same or greater number of competitive districts, and ran the chain for 10,000 steps.
- Texas: The team examined a rule to ensure that plans comply with the Voting Rights Act, a federal law that prohibits racial discrimination in voting. They found that by adding a constraint that preferentially selects plans with more districts that provide fair representation for minority groups, the resulting plans would have 2 to 3 more minority effective districts on average, based on 2010 data.
The student fellows who worked on this project included Rowana Ahmed, a master’s student in the Health Data Science program at Harvard University; Katherine Chang, a Ph.D. candidate in Education Policy, Organizations, and Leadership at the UW College of Education and an MPA student in Social Policy at the Evans School of Public Policy and Governance at UW; Ryan Goehrung, a Ph.D. candidate in the UW Department of Political Science; and Michael Souffrant, a Ph.D. candidate in Computational Biophysical Chemistry at Georgia State University. They worked with project lead Daryl DeFord, an Assistant Professor of Data Analytics in the Department of Mathematics and Statistics at Washington State University; and data scientists Bernease Herman, a Data Scientist at the eScience Institute, and Vaughn Iverson, a Research Scientist at the eScience Institute.
Learn more on the project blog and project website.
Dharma Dailey, the program’s Human Centered Design Mentor, noted that both teams connected with stakeholders to inform their work, and carefully considered the impacts on individuals. “The minimum wage team had to design their project in a manner that protected the privacy of millions of individuals represented in a large public administrative data set even as they strove to tease out otherwise unseen trends specific to low-wage workers. Meanwhile, the redistricting team aimed to broaden understanding among politicians, map-makers, and civil society of newly developed statistical tools that can better align voting maps with democratic principles,” she said.
This was the seventh year of the DSSG program at UW, which is one of the longest running programs of its kind. The DSSG Program Director is Sarah Stone, Executive Director of the eScience Institute, and the Program Chair is Anissa Tanweer, Research Scientist at eScience. To learn more about submitting a project proposal or becoming a student fellow in our 2022 DSSG program, check out the program website. Final presentations can be viewed here.