

This year, two interdisciplinary teams at the eScience Institute’s Data Science for Social Good (DSSG) program tackled timely issues, conducting projects to identify disinformation articles about the coronavirus and detect minority vote dilution resulting from geographic boundary setting in state, city, county and school board districts.
On August 19th, the DSSG student fellows presented the results of their projects, conducted with project leads and data scientists, to more than 130 people via zoom. The ten-week summer program joins student fellows from universities around the country with data and domain researchers, and real-world stakeholders, to work on collaborative projects for societal benefit. This year the program took place remotely for the first time due to the coronavirus pandemic.
The event featured opening remarks by Micron Technology president and CEO Sanjay Mehrotra and UW College of Engineering Dean Nancy Allbritton.
“Social impact work, like that being carried out by the Data Science for Social Good initiative, is a top priority for the College of Engineering. As dean of the College, it is inspiring to see participating students develop innovative, data-based solutions to urgent problems that we are facing right now. Thanks to the generous support of Micron, more students will be able to access this program which provides not only hands-on learning, but an opportunity for translational research for the public sector. I am proud to see our students working together with the community to impact pressing societal challenges,” said Dean Allbritton.
“Micron’s vision is transforming how the world uses information to enrich life for all, and the ‘for all’ is an important point of emphasis for us,” Sanjay Mehrotra told the research teams. “We want to make sure that everyone realizes the benefits of our data-driven solutions. That’s why it is so critical that AI algorithms have ethics, privacy, integrity and security built into them. This is important and vital research, and I’m thrilled to have Micron sponsoring it.”
This year, the DSSG program partnered with the Micron Foundation as a recipient of Micron’s Advancing Curiosity Award. Through this partnership, the DSSG offered the Micron Opportunity Award for the first time to students requiring additional financial support to participate in the program. Micron also supported student fellow stipends and resources for remote work. This program would not have been possible without this generous new support, along with continuing support from the University of Washington.
Descriptions of this year’s two projects and their final outcomes are below:
eiCompare: Making Every Vote Count
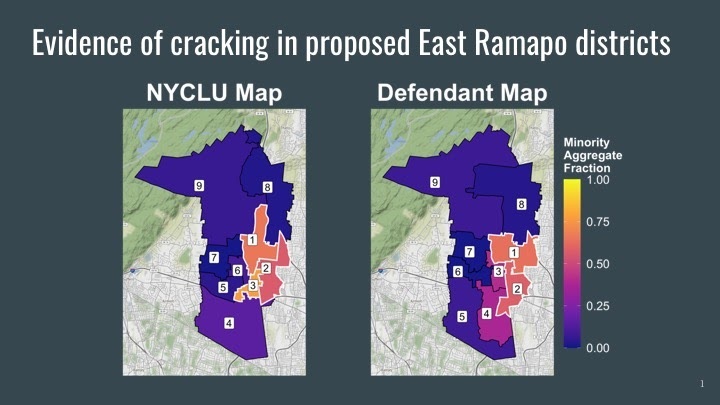
This project significantly enhances a software package called eiCompare that identifies minority vote dilution in city, county, state and school board districts with racially polarized voting patterns. The software is used in court cases to argue for redrawing district boundaries to uphold the right to equal representation in the Voting Rights Act. The project was largely based on a recent court case in East Ramapo, New York, in which minority vote dilution shown by eiCompare was used as evidence. The software will be pivotal in national redistricting next year following the 2020 U.S. Census. Minority vote dilution is proven by showing that a large, geographically compact and politically cohesive minority group is unable to elect preferred candidates due to “bloc voting” by the majority. However, these criteria are difficult to prove because ballot choices are confidential and voter registration files in most states do not identify race.
To accommodate these complexities, the software uses Ecological Inference (EI) methods to estimate percentages of racial groups that voted for each candidate in prior elections, to evaluate existing district boundaries and assess new district maps created by opposing parties in court. These processes, newly improved by the DSSG team, consist of geocoding addresses from voter files to merge them with racial data from the U.S. Census, using Bayesian Improved Surname Geocoding (BISG) to infer individual voter race from surname and location patterns in the Census, and aggregating and merging these data with election results at the voting precinct level to predict turnout in future elections. The team members expanded the functionality of the software package, increased its statistical robustness and made it more accessible. Their work ranged from testing geocoders, which convert addresses from voter files to latitude and longitude coordinates on a map as required by BISG, and comparing BISG results to counts of self-reported race in one state that collects race in voter registration files, to meeting with lawyers and data scientists at voting rights organizations.
The fellows are Juandalyn Burke, a doctoral student in epidemiology at the University of Washington; Ari Decter-Frain, a doctoral student in policy analysis and management at Cornell University; Hikari Murayama, a master’s student in the Energy and Resources Group at the University of California (UC) Berkeley; and Pratik Sachdeva, a doctoral student in physics at UC Berkeley. They worked with project leads Matt A. Barreto, professor of political science and Chicana/o Studies at UCLA, and Loren Collingwood, associate professor of political science at UC Riverside; and data scientists Scott Henderson, a research scientist in the Department of Earth and Space Sciences and data science fellow at the eScience Institute, and Spencer Wood, a research scientist at the eScience Institute and senior research scientist with EarthLab.
The project yielded the following new additions to the software package:
- New functions for cleaning, standardizing and manipulating data to improve the accuracy of results; and added geocoding functions for the first time.
- The ability to create data visualizations like density plots quickly and easily for court cases.
- Implementation of parallel processing to increase speed.
- Creation of “error bars” to calculate uncertainty in BISG estimates analytically and computationally.
- Tutorials on geocoding, BISG, EI, parallel processing, and data visualization.
- A guide for users to contribute to the package through Github pull requests.
Learn more on the project blog and project website.
Identifying Coronavirus Disinformation Online
This project creates an open source model to identify disinformation articles about the coronavirus using machine learning and natural language processing techniques. The tool is being designed in partnership with the nonprofit organization Global Disinformation Index (GDI), which works to defund disinformation sources by identifying high-risk websites for advertising technology companies that sell ads to websites automatically for companies and organizations. Since the sales happen in real time, with ads loading in seconds before each website is launched, there is no systematic review of website content. This tool will help GDI to flag websites that have a large quantity of disinformation articles, defined as intentionally deceptive or adversarial in nature, to help advertisers avoid placing ads there.
To create a prediction model that automatically classifies coronavirus articles as legitimate news or disinformation, the team created a neural network algorithm that examines word patterns and the context in which they appear and applies these patterns to analyze new inputs – similar to an email spam filter. They trained the model using 28,000 web-scraped articles, hand-labeled by GDI from March to June 2020, in addition to metadata. The team pre-processed the data to remove duplicates, special characters, embedded links and insignificant words such as “the”, and then converted the remaining text into a list of numbers, based on commonalities between words, to feed into the algorithm. They conducted experiments to identify features, such as linguistic patterns, to differentiate the articles, and critically examined the assumptions of each potential approach before finalizing their model. Challenges included producing a model that is adaptable to the constantly evolving nature of disinformation, and preventing the accidental misclassification of legitimate articles.
The project team includes fellows George Hope Chidziwisano, a doctoral candidate in media and information at Michigan State University; Richa Gupta, a master’s student in quantitative methods in the social sciences at Columbia University; Kseniya Husak, a master’s student in public policy and information science at the University of Michigan; and Maya Luetke, a doctoral candidate in epidemiology at Indiana University, Bloomington. The project is led by Maggie Engler, Lead Data Scientist, and Lucas Wright, Senior Researcher, at GDI. Technical guidance is provided by Noah Benson, a senior data scientist, and Vaughn Iverson, a senior research scientist at the eScience Institute.
The team’s work yielded the following outcomes and recommendations:
- Tested 72 permutations of network architectures and hyper-parameters to create a prototype.
- Recommended further experimentation with different features and algorithms, and exploration of the interpretability of neural networks to ensure transparency.
- Model accurately classified 2,268 out of 2,420 disinformation articles tested (93.7%).
- Model misclassified 131 articles as disinformation out of 4,685 legitimate articles tested (2.8%), highlighting the importance of additional work to avoid unintended impacts.
- Recommended that human review and retraining the model as disinformation narratives change are essential to the success of the classifier.
- Added open source code to Github for other researchers to use.
Learn more on the project blog and project website.
The eScience Institute’s DSSG program is now one of the longest running initiatives of its kind, giving visibility to the University of Washington for this important work in translational data science. DSSG Program Director Sarah Stone notes, “As a community and through this program, we are exploring and defining the space of using data science in the public setting responsibly, while understanding the inherent importance of bringing a diverse community of practitioners to the table.”
To learn more about submitting a project proposal or becoming a student fellow in our 2021 DSSG program, check out the program website. Final presentations can be viewed here.