Project Lead: Sarah Dreier, UW Department of Political Science and Paul G. Allen School of Computer Science Engineering Postdoctoral Fellow
eScience Liaison: Jose Hernandez
How do liberal democracies justify policies that violate the rights of targeted citizens? When facing real or perceived national security threats, democratic states routinely frame certain citizens as “enemies of the state” and subsequently undermine those citizens’ freedom and liberties. This Incubator project uses natural language processing (NLP) techniques on digitized archive documents to identify and model how United Kingdom government officials internally justified their decisions to intern un-convicted Irish Catholics without trial during its “Troubles with Northern Ireland.” This project uses three NLP approaches—dictionary methods, word vectors, and adaptions of pre-trained models—to examine if/how government justifications can be identified in text. Each approach is based on, validated by, and/or trained on hand-coded annotation and classification of all justifications in the corpus (the “ground truth”), which was executed prior to the start of this project. In doing so, this project seeks to advance knowledge about government human rights violations and to explore the use of NLP on rich, nuanced, and “messy” archive text. More broadly, this project models the promise of combining archive text, qualitative coding, and computational techniques in social science. This project is funded by NSF Award #1823547; Principal Investigators: Emily Gade, Noah Smith, and Michael McCann.

Project Results
This project yielded four products: cleaned text corpora, binary and multi-class machine learning text classifiers, word embeddings based on digitized archive text, and a shallow neural network model for predicting text classification.
First, we prepared qualitatively coded material into datasets for descriptive visualization and NLP analysis, including: a complete archive corpus of all digitized text from +7,000 archive pages, a corpus of all ground-truth incidents of government justifications for internment without trial, and graphic representations of justification categories and frequencies over time.
Second, we explored training a machine-learning model, using binary and multi-class text classification, to classify a specific justification entry into its appropriate category. We used a “bag of words” approach, which trains a classifier based on the presence and frequency of words in a given entry. A simple binary model classified justification entries relatively well, achieving between 75-90% accuracy among the most prominent categories. The unigram and bi-gram terms most associated with each category’s binary classification also contributed to our substantive knowledge about our classification categories. Next, we assessed and tuned a more sophisticated multi-class classifier to distinguish among six justification categories. The best-performing machine learning classifier—a logistic regression model based on stemmed unigrams (excluding English stopwords and those that occurred fewer than 10 times in the corpus)—classified justification entries into six pre-determined categories with approximately 43% accuracy, which is an improvement upon random. These classifiers suggest that our justification corpus contains signals for training machine learning tasks, despite the imperfections associated with digitized archive text.
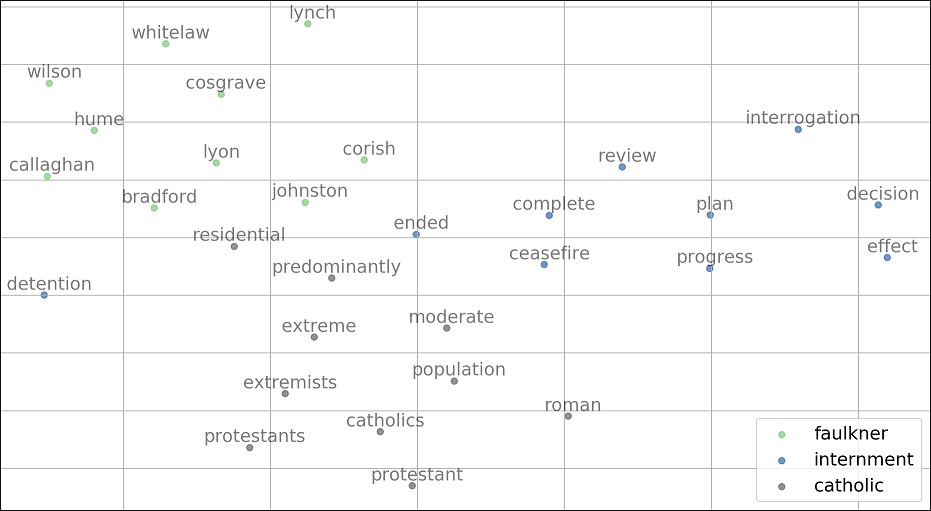
Finally, we developed a deep-learning approach to predicting a justification entry’s classification (Jurafsky and Martin 2019). This allowed us to leverage a given word’s semantic and syntactic meaning (using pre-trained word embeddings) to aid our classification task. Because we expected our text data to contain nuances and context-specific idiosyncrasies, we developed word embeddings based on our complete archive-based corpus. These embeddings proved to be meaningful and informative, despite our imperfect data—which is relatively limited in size and contains considerable errors, omissions, and duplication (See Figure 2). Using these archive-based word embeddings, we built a shallow Convolutional Neural Network (CNN) to predict a sentence-based justification entry’s classification (Kim 2014). Our preliminary CNN—which, at the time of this writing, is over-fitted to the training data and only achieves around 30% accuracy when classifying testing data—serves as the basis for further fine-tuning.
Together, these products lay the groundwork for analyzing government justifications for internment, continuing to develop machine-learning approaches to identifying government justifications for human rights violations, and modeling how NLP techniques can aid the analysis of real-world political or government-related material (and for archived texts more generally).
References
Jurafsky, Daniel and James H. Martin. 2019. “Neural Networks and Neural Language Models.” In Speech & Language Processing: An Introduction to Natural Language Processing, Computational Linguistics, and Speech Recognition. Draft of October 2, 2019.
Kim, Yoon. 2014. “Convolutional Neural Networks for Sentence Classification.” arXiv:1408.5882v2 [cs.CL] 3 Sep 2014.
View the final presentation here.