Project Leads: Nora Webb Williams, PhD Candidate, Department of Political Science; Wesley Zuidema, PhD Student, Department of Political Science; John D. Wilkerson, Professor, Department of Political Science; and Andreu Casas, Moore Sloan Research Fellow, New York University
eScience Liaison: Bernease Herman
How do outsider political groups use social media to mobilize supporters online? What types of social media techniques, messages and images are most likely to capture attention and motivate action? Prior research demonstrates the people are more responsive to visual cues than text. We test whether images impact message sharing and followership, and if so, which types of images are the most effective at mobilizing supporters.
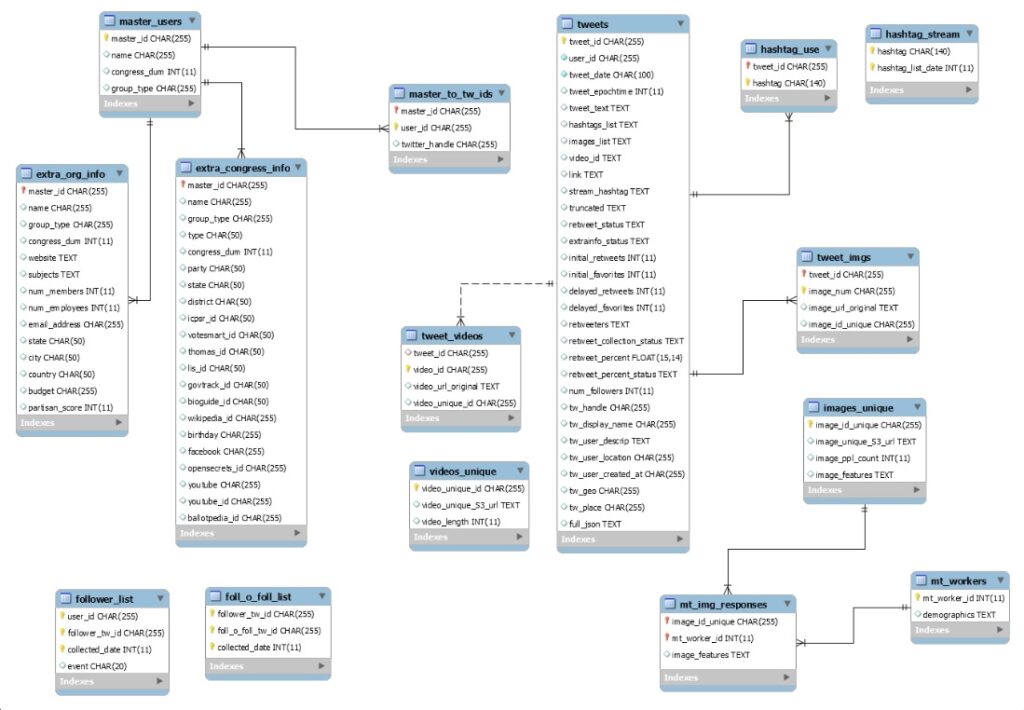
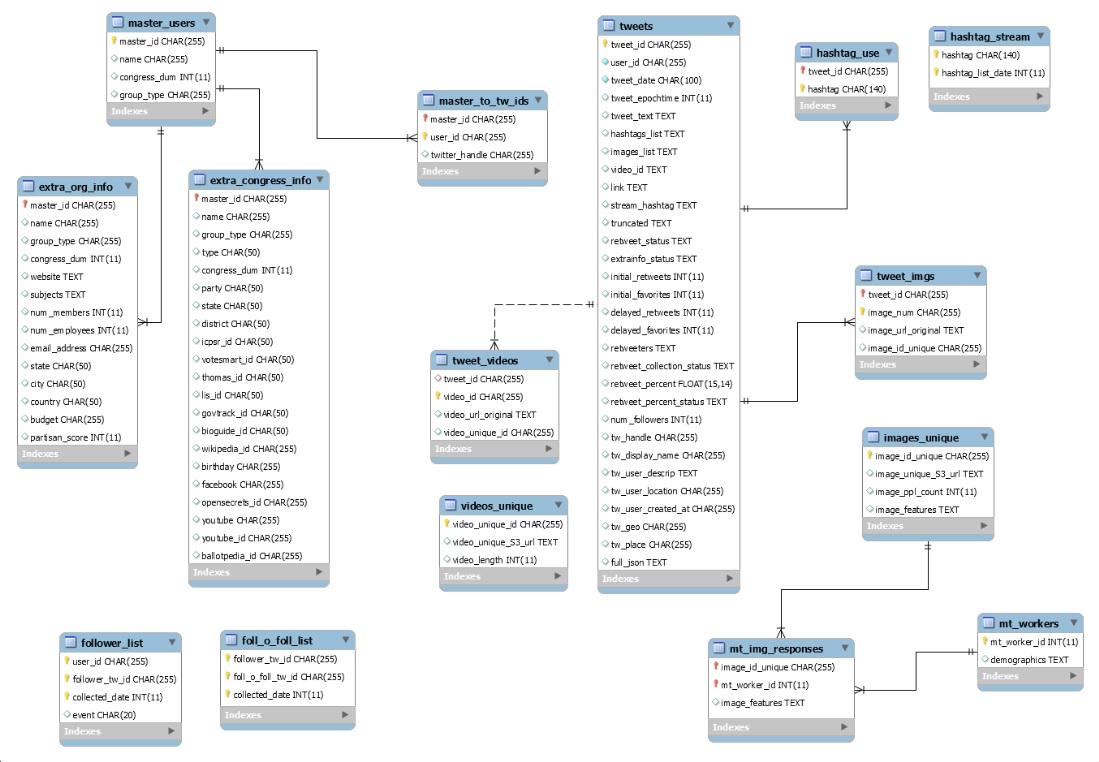
To begin to address these questions, we are tracking the Twitter posts of roughly 1,300 public affairs organizations (obtained from the Encyclopedia of Associations), national and state politicians (including every member of the 115th Congress), and news organizations. For each tracked account, we are streaming all tweets, collecting any accompanying images or videos, and periodically collecting account data (e.g., the number of account followers). We are also streaming tweets for every hashtag that one of these organizations uses more than once, with some standard exclusions. For example, if any organization uses the hashtag #LasVegasShooting more than once, we automatically start collecting the entire stream of #LasVegasShooting tweets by all organizations and individuals.
One purpose of the methodology is to capture social mobilization efforts in their early stages – something we could not do if we were to focus on known successful cases. There are many potential questions that could be addressed with the data, however. The challenge, from a data management perspective, is that these overlapping processes are producing a large quantity of data. The Twitter data collection is ongoing, and we will soon embark on a secondary stage of data collection, hiring annotators on Mechanical Turk to provide labels for each collected image (for example, we will ask how much sadness a respondent feels after looking at a given image). Currently all of the data is stored in AWS S3 buckets.