Project Lead: Nicoleta Cristea, Civil and Environmental Engineering, University of Washington
Project Collaborators: Jessica Lundquist, Ryan Currier, Karl Lapo
eScience Liaisons: Anthony Arendt, Rob Fatland
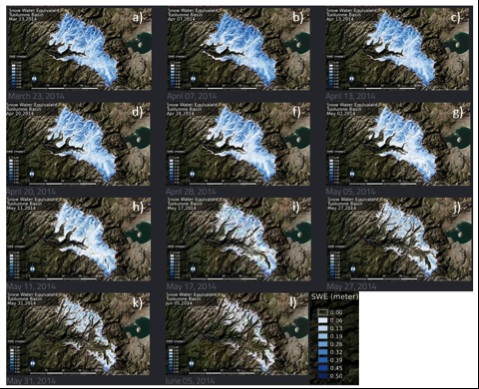
Large, spatially distributed datasets have increasingly become more abundant, but there is currently no workflow that efficiently manages, analyzes and visualizes these datasets, ultimately dampening their usability and assistance in water resource management/research. Within the incubator, we envision creating a workflow based on the existing weather model generated meteorology files (1TB spatio-temporal) and LiDAR-derived snow depth spatial datasets, 1-9 GB (Figure 1) to be applicable to other existing or incoming data. The workflow will help integrate high-resolution spatio-temporal datasets with hydrologic modeling to improve water resources management.
The main goal of this project during the incubator is to explore different methods for computing and cloud storage that may increase data processing efficiency. Besides performance issues around minimizing processing time in the context of dataset size, practical issues of migration of software licenses are also being explored. The group has been working on determining how to partition data processing capabilities between the cloud and local machines. In order to evaluate this, the team is testing two cases – cloud computing with new code (Python), which does not require a license, and using existing code with a license required (Matlab). To use the Xarray Python package, it was necessary to convert the data from the original format to a contiguous time series for the region of interest. This code is in the process of being tested in Azure.
The next steps for this project are to finish testing cloud computing methods for the Python code, and to use existing Matlab code to downscale coarse resolution fractional snow covered area datasets to high resolution binary snow data (presence or absence) for further testing. Additionally, they will determine what sort of data are good candidates for cloud computing, and at what point the time and cost of cloud computing becomes a better option than local computing resources.