Project Lead: Ian Kelley, Ph.D., Research Consultant, Information School
eScience Liaison: Andrew Whitaker, Ph.D., Research Scientist, eScience Institute
The pervasive and rich data available in today’s networked computing environment provides many major opportunities for innovative data-intensive applications. Particularly challenging are data analysis projects that rely upon input from millions of sparse, highly dimensional, and dirty data files at can be difficult and time consuming to analyze.
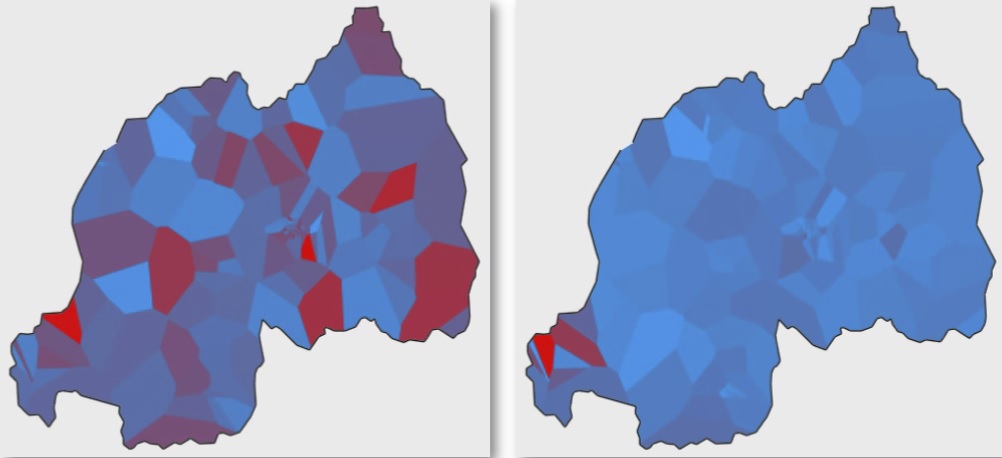
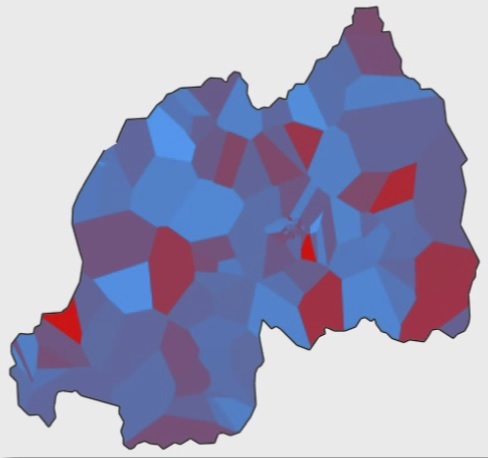
The goal of this project was to develop methods and infrastructure for analyzing large-scale call detail record (CDR) data. The first goal of this investigation was to identify the computational and logistical challenges that existed when collecting, storing, and analyzing this type of data. The next stage focused on evaluating different tools, environments, and middle-ware that could support the data workflows needed to analyze this data. Due to the size, heterogeneity, and scale of the datasets, project scope and emphasis focused on current state-of-the-art “big data” systems such as MapReduce, Hive, Shark, and Spark.
Call Detail Records (CDRs) are one such set of information artifacts, consisting of metadata about mobile phone network calls that are passively collected in log files. These records can provide rich information that is useful for explorations ranging from mobility analysis and location inference to calculating probabilities of new product adoption.