Project Leads: Emily Gade (Political Science)
eScience Liaison: Andrew Whitaker
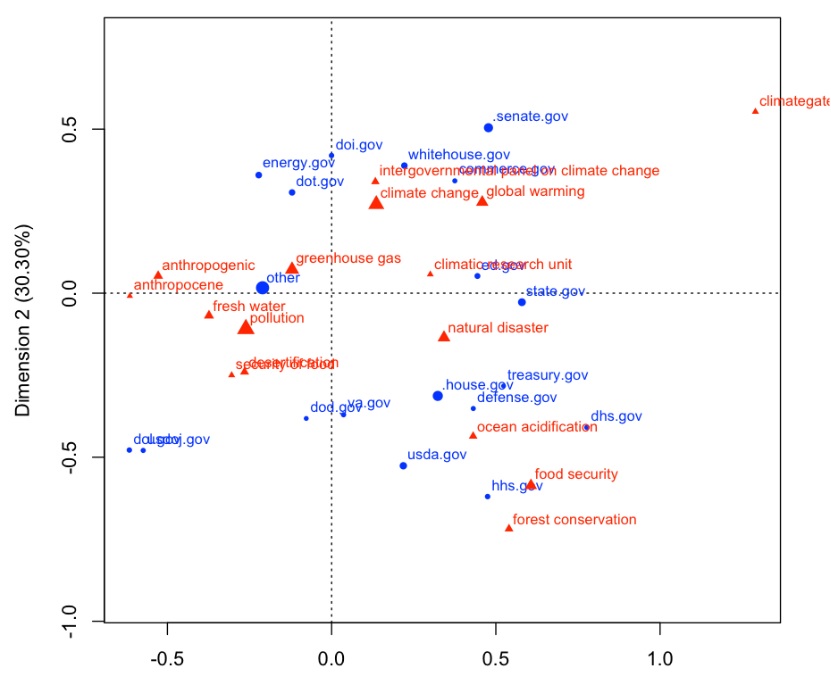
Data are revolutionizing all fields of science including political science. Managing unstructured data (particularly text) is a non-trivial challenge for social scientists, especially at a large scale. An example is the .gov dataset curated by the Internet Archive (IA). The IA curates web crawls from 1996 to the present, and has carved out a database of all .gov pages. These pages have been parsed so that it is possible to query (for example) just the .html text. The resulting 82 TB database (WARC format) is currently hosted pro bono by a private company (Altiscale), distributed across a dozen or so servers. Running a query via Hadoop takes about 2 days. Investigating research questions using Altiscale is a very time consuming process (and beyond the technical ability of nearly all political scientists). As well, we hope to identify and circumvent key challenges faced as a result of non-scientific research design that were used for web crawls and the changing nature of content now posted on the web.